
来源:爱范儿

日前,OpenAI 公布了一项 AI 健康系统评估标准「HealthBench」,号称「最具 AGI 标志性」。
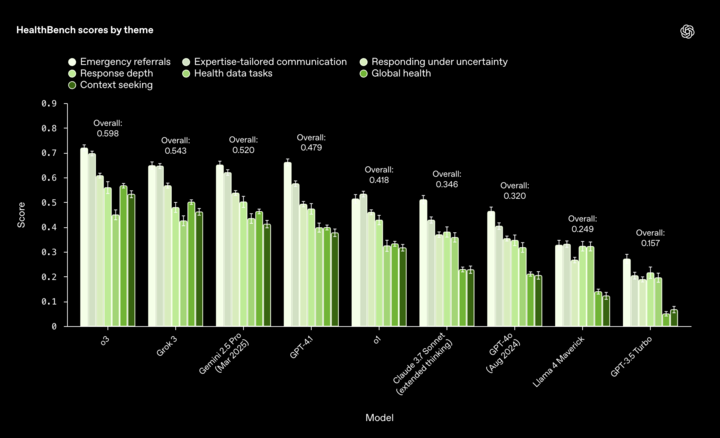
具体来看,HealthBench 旨在更好地衡量 AI 系统在医疗领域的性能表现。该基准是由 OpenAI 与全球 60 个国家,262 名职业医生共同打造,包含了 5000 个真实的医疗对话,并且每个对话都有医生定制的评分标准,从而评估模型的回答。
HealthBench 的模型性能测试结果中,表现最好的是 OpenAI 自家的 o3 模型,拿下最高分并位列第一,Grok 3 和 Gemini 2.5 Pro 分别排名第二和第三,同时 o3 也在基准测试中超越了 Claude 3.7 Sonnet。OpenAI 方面表示,近几个月来,其前沿模型在 HealthBench 中的表现提高了 28%。
可靠性方面,OpenAI 在 HealthBench 上评估了各模型在 k 个样本下的最差表现。结果显示,o3 在 16 个样本时最差的分数,超过了 GPT-4o 的两倍。
而最具看头的应该就是大模型 PK 真人医生了。OpenAI 将 262 名医生分为了「凭自己本事」和「依靠 AI 进行更高质量回答」两个组别。随后 AI 自主生成的回答,通过比对前面两组的回答进行评测 PK,并评估大模型在准确性、专业性、实用性等方面的表现。
从 2024 年 9 月的模型(o1-preview、4o)来看,仅靠 AI 生成的回答优于「凭自身本事」的医生回答。
而从 2025 年 4 月的模型(o3、GPT-4.1)来看,AI 生成的回答已经与「依靠 AI 进行更高质量回答」的医生回答,质量上没有显著的差距了。
更多详细内容可以访问 OpenAI 的官方技术报告进行了解:https://openai.com/index/healthbench/
本文转载自爱范儿,本文观点不代表雅典娜AI助手YadiannaAI立场。
